Repositorio de datos sintéticos OMOP
Descripción del componente
OMOP (Observational Medical Outcomes Partnership) es un modelo de datos clínicos desarrollado y mantenido por la asociación sin ánimo de lucro OHDSI (Observational Health Data Sciences and Informatics), que se ha convertido durante los últimos años en un estándar de facto para la organización de datos clínicos en proyectos de investigación observacional, especialmente en aquellos de carácter distribuido o multicéntrico. OMOP ofrece, además de un modelo común de datos desde el punto de vista estructural, una especificación muy detallada acerca de qué y cómo se debe registrar cada concepto clínico en el modelo, gracias a una terminología clínica extensísima, que integra la mayoría de terminologías y ontologías utilizadas habitualmente en el contexto biomédico.
Este repositorio de datos sintéticos OMOP que forma parte de la implementación de referencia de IMPaCT-Data, tiene las siguientes características:
Contenedor Docker con todos los elementos necesarios para desplegar el repositorio OMOP en unos segundos, en cualquier equipo que disponga del software necesario (Docker y docker-compose)
El despliegue se ha configurado utilizando docker-compose, de manera que resulte muy sencillo integrar el modelo con otras herramientas también contenedorizadas
Gestor de Base de Datos Postgres 13.0 sobre el que se ha desplegado el modelo OMOP
Esquema completo de OMOP-CDM versión 5.3
Tablas específicas para el registro de radiómica: imaging_feature e imagin_occurrence
Versión de vocabulario: v5.0 (ago-2024)
Con objeto de poder testar y validar fácilmente scripts analíticos, consultas de búsqueda de datos o cualquiera de las herramientas proporcionadas por OHDSI para trabajar con datos clínicos sobre un modelo OMOP, es necesario disponer no solo del modelo de datos, sino de algunos datos que permitan asegurarse de que las herramientas y el código a ejecutar no contiene errores sintácticos, y que los resultados obtenidos son consistentes, antes de proceder a desplegarlos sobre un contexto real y completo. Para estas operaciones, resulta muy útil disponer de datos sintéticos que, si bien tienen la estructura, características y variabilidad esperables en un conjunto de datos real, no comprometan la privacidad de pacientes reales ni exijan autorizaciones o procesos de evaluación adicionales, que complican considerablemente el desarrollo de estas fases previas de un proyecto de investigación.
Por este motivo, el componente aquí descrito se ha poblado con datos variados de los distintos dominios de información clínica (diagnósticos y síntomas, observaciones, mediciones analíticas, pruebas diagnósticas y terapéuticas, prescripción farmacéutica y radiómica) correspondientes a pacientes ficticios, que no tienen consideración de datos personales, y por tanto pueden ser utilizados con total libertad.
Los vocabularios que integra OMOP en su modelo son muy numerosos, y constan de millones de conceptos y términos clínicos. Estos vocabularios no se han incluido inicialmente en la implementación de referencia, por razones de licenciamiento (son propiedad de OHDSI aunque sean de acceso gratuito), por actualización de los mismos, y por el gran volumen que supone una descarga inicial de los mismos. Por tanto, será preciso por parte de quien descargue y configure un repositorio OMOP localmente, que previamente acceda al sitio web de ATHENA https://athena.ohdsi.org/vocabulary/list, y descargue un vocabulario personalizado. Para la base de datos sintética incluida, y para cubrir las necesidades terminológicas más frecuentes en el contexto clínico español, sugerimos la siguiente configuración mínima de vocabularios a descargar, quedando a voluntad del implementador final la incorporación de vocabularios adicionales:
SNOMED - Systematic Nomenclature of Medicine - Clinical Terms (IHTSDO)
ICD9CM - International Classification of Diseases, Ninth Revision, Clinical Modification, Volume 1 and 2 (NCHS)
ICD9Proc - International Classification of Diseases, Ninth Revision, Clinical Modification, Volume 3 (NCHS)
HCPCS - Healthcare Common Procedure Coding System (CMS)
LOINC - Logical Observation Identifiers Names and Codes (Regenstrief Institute)
RxNorm - RxNorm (NLM)
NDC - National Drug Code (FDA and manufacturers)
Gender - OMOP Gender
Race - Race and Ethnicity Code Set (USBC)
CMS Place of Service - Place of Service Codes for Professional Claims (CMS)
ATC - WHO Anatomic Therapeutic Chemical Classification
Ethnicity - OMOP Ethnicity
NUCC - National Uniform Claim Committee Health Care Provider Taxonomy Code Set (NUCC)
ICD10CM - International Classification of Diseases, Tenth Revision, Clinical Modification (NCHS)
ABMS - Provider Specialty (American Board of Medical Specialties)
RxNorm Extension - OMOP RxNorm Extension
CVX - CDC Vaccine Administered CVX (NCIRD)
Nebraska Lexicon - Nebraska Lexicon (UNMC)
OMOP Extension - OMOP Extension (OHDSI)
Creación del contenedor OMOP-Synthetic
Requisitos iniciales:
En el equipo o servidor donde se desplegará el contenedor de datos sintéticos, se debe tener instalado el siguiente software:
S.O. Linux (recomendado, aunque debería funcionar también en Windows y MacOS)
Docker
Docker-compose
Git
Clonación y despliegue del repositorio
Los pasos para clonar y desplegar el repositorio de datos sintéticos son los siguientes:
Crear un directorio (lo llamaremos [OMOP-SYNTHETIC-REPO]) en el equipo donde se desplegará el repositorio, y entrar en dicho directorio.
Clonar el repositorio de gitlab con todos los ficheros y scripts para crear el repositorio desde el servicio gitlab del BSC:
$ git clone https://gitlab.bsc.es/impact-data/iacs/omop-synthetic-repo.git
La estructura del repositorio git es la siguiente:
docker-compose.yml: Fichero con la configuración para levantar el contendor docker con el repositorio OMOP
initdb: Scripts para crear el esquema OMOP y poblar todas las tablas la primera vez que se crea y levanta el contenedor.
datasets: Carpeta que contiene los datos para poblar la base de datos con el esquema y los datos sintéticos.
vocabulary: Carpeta donde se deben colocar los ficheros con el vocabulario OMOP descargado desde Athena.
Synthetic_data: Carpeta con los datos sintéticos para cargar en el esquema.
Antes de crear y desplegar el contenedor OMOP, es preciso acceder a la página web de Athena https://athena.ohdsi.org/vocabulary/list, y descargar los vocabularios deseados. Una vez descargados, deben descomprimirse y copiarse en la carpeta [OMOP-SYNTHETIC-REPO]/datasets/Vocabulary. Más información en el README del mencionado directorio.
Una vez copiados los ficheros CSV que contienen los vocabularios de OMOP, desde la carpeta principal del repositorio [OMOP-SYNTHETIC-REPO], ejecutaremos
$ docker compose up -d
Esta instrucción levantará un contenedor con PostgreSQL v.13, y cargará en el mismo todas las tablas, tanto las de vocabularios OMOP, como los datos sintéticos incluidos en la carpeta datasets/Synthetic_data.
La primera vez que creamos el contenedor, el proceso de carga de los datos puede tardar bastante tiempo, dado que tiene que cargar millones de registros de conceptos y referencias. Dependiendo de la capacidad y velocidad del equipo en el que se ejecuta, puede tardar media hora o más.
Una forma de visualizar la correcta ejecución del proceso de carga, y de detectar cualquier eventual error en la carga, es ejecutar el comando:
$ docker compose logs -f postgres-omop
Si se desea crear el repositorio OMOP con todos los vocabularios, pero sin datos sintéticos, con objeto de utilizarlo para poblarlo con datos reales, basta con borrar el fichero “import_data.sql” de la carpeta “initdb”.
Si no se desea cargar tampoco las tablas no estándar para el registro de radiómica, tendremos que borrar el fichero “import_image_extension.sql” de la carpeta “initdb”.
Una vez levantado el contenedor, la base de datos OMOP es accesible a través del puerto 5432 de la máquina local (localhost:5432).
Para detener el contenedor, ejecutaremos:
$ docker compose down
Este comando detiene y borra el contenedor, pero no los datos cargados, que se encuentran en el directorio [OMOP-synthetic-repo]/data, por lo que una nueva carga del contenedor (docker compose up -d) no necesitará releer los datos, y el arranque se realiza en unos pocos segundos.
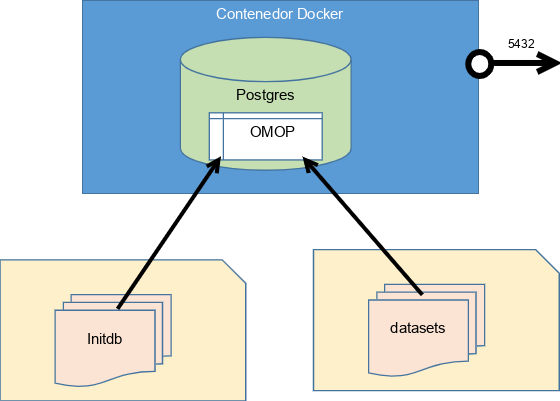
Esquema del funcionamiento del repositorio de datos sintéticos OMOP
Documentación técnica
Documentación técnica
Repositorio de código
Contacto
Para cualquier duda durante el periodo de uso y validación de los componentes de la Implementación de Referencia de IMPaCT-Data (Marzo, 2025), podéis poneros en contacto con: